¶ 제5장: 행렬과 왜곡 (Matrix & Distortion) - 공간을 빚어내는 보이지 않는 손
¶ 5.1 서론: 숫자의 감옥에서 탈출하여 공간의 춤으로
¶ 5.1.1 엑셀 시트 너머의 세계
인공지능(AI)과 데이터 과학의 입문자들이 처음 선형대수학을 접할 때 가장 흔하게 범하는 오류는 행렬(Matrix)을 단순히 '직사각형 모양으로 배열된 숫자의 표'라고 인식하는 것이다. 물론 컴퓨터 공학적인 관점에서, 특히 파이썬(Python)의 리스트(List)나 2차원 배열(Array)로 행렬을 구현할 때 이러한 데이터 구조적 접근은 직관적이고 효율적이다. 엑셀 스프레드시트가 데이터를 행과 열로 정리하듯, 행렬도 데이터를 담는 그릇(Container)으로 기능하는 것은 부정할 수 없는 사실이다.
그러나 현대 인공지능, 특히 딥러닝(Deep Learning)의 심장부에서 벌어지는 일들을 진정으로 이해하고자 한다면, 우리는 이 정적인 '저장소'로서의 관점을 과감히 버려야 한다. 본 장에서는 행렬을 데이터를 보관하는 창고가 아니라, 데이터가 속해 있는 공간 자체를 비틀고, 늘리고, 회전시키며, 때로는 차원을 붕괴시키는 역동적인 '함수(Function)' 이자 '기계(Machine)' 로 재정의한다.
우리가 다루는 데이터 벡터(Vector)를 공간상의 한 점, 혹은 원점에서 뻗어 나가는 화살표라고 상상해 보자.
행렬은 이 화살표를 움켜쥐고 다른 위치로 옮겨놓는 변환 장치다.
입력 벡터 가 행렬 라는 기계에 들어가면,
라는 새로운 벡터가 되어 출력된다.
이 과정에서 행렬은 마치 렌즈(Lens)처럼 작용한다.
광학 렌즈가 빛의 경로를 굴절시켜 상을 확대하거나 축소하고 초점을 맞추듯,
행렬은 고차원 데이터 공간의 ‘빛’을 굴절시켜
우리가 원하는 형태로 데이터를 변형시킨다.
¶ 5.1.2 딥러닝: 공간 왜곡의 연속
심층 신경망(Deep Neural Network)은 본질적으로 이러한 행렬 연산의 거대한 사슬이다. 입력 데이터(예: 이미지의 픽셀 값, 문장의 토큰 임베딩)가 첫 번째 층(Layer)을 통과한다는 것은, 첫 번째 가중치 행렬(Weight Matrix)에 의해 공간이 한 차례 왜곡된다는 것을 의미한다. 이어지는 활성화 함수(Activation Function)는 선형적으로 변환된 공간을 비선형적으로 구부린다(Fold). 이 과정을 수십, 수백 번 반복함으로써 신경망은 복잡하게 뒤엉킨 데이터의 실타래를 풀어내어, 고양이와 강아지를 구분할 수 있는 선형 분리 가능한(Linearly Separable) 형태로 공간을 재배치한다.
이 장의 목표는 독자에게 '행렬의 눈'을 뜨게 하는 것이다. 2×22 \times 22×2 행렬의 숫자 네 개를 보았을 때, 단순히 수식 계산을 떠올리는 것이 아니라, 공간이 어느 방향으로 기울어지고(Shear), 얼마나 팽창하며(Scale), 회전하는지가 머릿속에 홀로그램처럼 그려져야 한다. 이러한 기하학적 직관(Geometric Intuition)이야말로 난해한 수식 뒤에 숨겨진 AI 모델의 작동 원리를 꿰뚫어 보는 통찰력을 제공한다.
우리는 이제부터 선형 변환의 기초부터 시작하여, 행렬식(Determinant)이 의미하는 부피의 변화, 고유값(Eigenvalue)이 가리키는 회전의 축, 그리고 현대 거대 언어 모델(LLM) 튜닝의 핵심 기술인 LoRA(Low-Rank Adaptation)에 이르기까지, 행렬이 빚어내는 공간 왜곡의 드라마를 상세히 추적할 것이다.
¶ 5.2 선형 변환(Linear Transformation): 공간을 조작하는 규칙
¶ 5.2.1 선형성의 두 가지 철칙
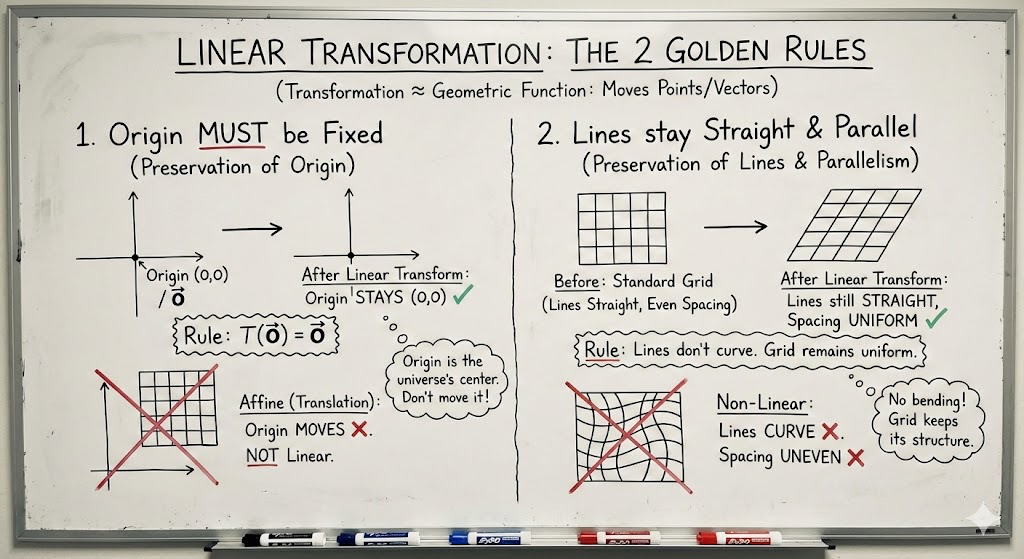
'변환(Transformation)'이라는 용어는 '함수(Function)'의 다른 말이다. 다만, 함수가 수(Number)를 받아 수를 뱉어내는 느낌이 강하다면, 변환은 점(Point)이나 벡터를 받아 다른 점이나 벡터로 이동시킨다는 기하학적 뉘앙스를 풍긴다. 그중에서도 '선형 변환(Linear Transformation)' 은 공간을 조작하는 데 있어 매우 엄격하고도 아름다운 두 가지 규칙을 따른다.
- 원점은 고정되어야 한다 (Preservation of Origin):
변환 전의 영벡터(0\mathbf{0}0)는 변환 후에도 반드시 영벡터 위치에 머물러야 한다. 만약 공간 전체가 평행 이동(Translation)하여 원점이 다른 곳으로 가버린다면, 그것은 선형 변환이 아니라 아핀 변환(Affine Transformation)의 영역이 된다. 선형 대수학의 세계에서 원점은 우주의 중심과 같아서 결코 흔들려서는 안 된다. - 직선은 직선으로 남고, 평행한 간격은 유지된다 (Preservation of Lines and Parallelism):
변환 전에 직선이었던 모든 선은 변환 후에도 휘어지지 않고 직선이어야 한다. 또한, 격자(Grid) 눈금들 사이의 간격이 균일했다면, 변환 후에도 그 간격은 (늘어나거나 줄어들 수언정) 서로 균일하게 유지되어야 한다.
이 두 가지 규칙 때문에 선형 변환은 공간을 구부리거나 찢을 수 없다. 오로지 공간을 늘리고(Stretch), 줄이고(Shrink), 회전시키고(Rotate), 밀어버리는(Shear) 조작만이 허용된다. 결과적으로, 원래 정사각형이었던 격자들은 변환 후에 반드시 평행사변형(Parallelogram) 꼴로 변하게 된다.
¶ 5.2.2 기저 벡터(Basis Vectors)의 추적: 행렬의 열(Column)이 말하는 것
공간 전체가 어떻게 움직이는지 파악하기 위해 무한히 많은 모든 벡터를 일일이 계산해 볼 필요는 없다. 선형성의 성질 덕분에, 우리는 오직 공간의 기준이 되는 '기저 벡터(Basis Vectors)' 들이 어디로 이동하는지만 추적하면 된다. 나머지는 모두 이들을 따라가기 때문이다.
2차원 평면 를 예로 들어보자.
표준 기저 벡터는 다음과 같다.
x축 방향의 단위 벡터:
y축 방향의 단위 벡터:
어떤 행렬 가 이 공간을 변환시킨다면,
이 기저 벡터들은 어디로 이동하게 될까?
놀랍게도, 행렬의 열(Column)들이 바로 변환된 기저 벡터의 좌표다.
행렬
가 있다고 하자.
이 행렬이 공간을 변환할 때, 각 열은 표준 기저 벡터가 도착하는 위치를 의미한다.
-
첫 번째 열:
는 x축 방향 단위 벡터 가 변환 후 도착하는 지점이다.
즉,
-
두 번째 열:
는 y축 방향 단위 벡터 가 변환 후 도착하는 지점이다.
즉,
이 사실은 행렬을 해석하는 가장 강력한 시각적 도구다. 예를 들어, A = \\begin{bmatrix} 2 & -1 \\ 1 & 1 \\end{bmatrix}라는 행렬을 보자.
- 첫 번째 열 beginbmatrix21endbmatrix\\begin{bmatrix} 2 \\\\ 1 \\end{bmatrix}beginbmatrix21endbmatrix: 원래 오른쪽으로 1칸 가던 hati\\hat{i}hati 벡터가, 오른쪽으로 2칸 위로 1칸 가는 위치로 잡아당겨졌다. 즉, x축이 (2,1)(2, 1)(2,1) 방향으로 길게 늘어났다.
- 두 번째 열 beginbmatrix−11endbmatrix\\begin{bmatrix} -1 \\\\ 1 \\end{bmatrix}beginbmatrix−11endbmatrix: 원래 위로 1칸 가던 hatj\\hat{j}hatj 벡터가, 왼쪽으로 1칸 위로 1칸 가는 위치로 기울어졌다. 즉, y축이 (−1,1)(-1, 1)(−1,1) 방향으로 쓰러졌다.
이 두 개의 새로운 벡터를 변(Edge)으로 하는 평행사변형을 그리면, 전체 공간이 어떻게 왜곡되었는지 완벽하게 시각화할 수 있다.
임의의 벡터 mathbfv=beginbmatrixxyendbmatrix\\mathbf{v} = \\begin{bmatrix} x \\ y \\end{bmatrix}mathbfv=beginbmatrixxyendbmatrix는 xhati+yhatjx\\hat{i} + y\\hat{j}xhati+yhatj이므로, 변환 후에는 x(textnewhati)+y(textnewhatj)x(\\text{new }\\hat{i}) + y(\\text{new }\\hat{j})x(textnewhati)+y(textnewhatj)가 된다.
¶ 5.2.3 주요 변환 유형의 시각적 해부
행렬의 성분 구성에 따라 공간 왜곡의 양상은 극적으로 달라진다. 주요 변환들을 기하학적으로 해부해보자.2
¶ 1. 스케일링 (Scaling): 공간의 호흡
대각 행렬(Diagonal Matrix) 형태는 각 축을 독립적으로 늘리거나 줄인다.
\\begin{bmatrix} k\_x & 0 \\\\ 0 & k\_y \\end
비대각 성분(Off-diagonal elements)이 0이라는 것은 x축과 y축이 서로 간섭하지 않고, 각자의 방향을 유지한 채 길이만 변한다는 뜻이다.
- k>1k > 1k>1: 해당 축 방향으로 공간이 팽창한다.
- 0<k<10 < k < 10<k<1: 해당 축 방향으로 공간이 압축된다.
- k<0k < 0k<0: 축을 기준으로 공간이 반전(Reflection)된다. 거울상처럼 뒤집힌다.
¶ 2. 전단 (Shear): 카드를 미는 손
전단 변환은 면적을 유지하면서 공간을 옆으로 미는 변환이다. 트럼프 카드 한 덱을 책상 위에 놓고 옆면을 밀었을 때 카드가 비스듬히 밀리는 모습을 상상하면 된다.
\\begin{bmatrix} 1 & k \\\\ 0 & 1 \\end
이 행렬은 첫 번째 열이 beginbmatrix10endbmatrix\\begin{bmatrix} 1 \\\\ 0 \\end{bmatrix}beginbmatrix10endbmatrix이므로 x축(hati\\hat{i}hati)은 움직이지 않고 고정된다. 그러나 두 번째 열은 beginbmatrixk1endbmatrix\\begin{bmatrix} k \\\\ 1 \\end{bmatrix}beginbmatrixk1endbmatrix이 되어, y축(hatj\\hat{j}hatj)이 x축 방향으로 kkk만큼 미끄러진다. 수평 격자선들은 여전히 수평을 유지하지만, 수직 격자선들은 오른쪽(혹은 왼쪽)으로 kkk의 기울기만큼 기울어진다.18 전단 변환은 데이터의 상관관계를 인위적으로 만들어내거나 제거할 때 유용하게 쓰인다.
¶ 3. 회전 (Rotation): 원점의 춤
회전 변환은 공간의 형태를 일그러뜨리지 않고(Rigid Body Motion), 원점을 중심으로 전체를 돌린다.
\\begin{bmatrix} \\cos\\theta & -\\sin\\theta \\\\ \\sin\\theta & \\cos\\theta \\end
이 행렬은 직교 행렬(Orthogonal Matrix)의 대표적인 예로, 행렬식(Determinant)이 1이며, 전치 행렬이 곧 역행렬이 되는 특성을 가진다. hati\\hat{i}hati 벡터는 (costheta,sintheta)(\\cos\\theta, \\sin\\theta)(costheta,sintheta)로, hatj\\hat{j}hatj 벡터는 (−sintheta,costheta)(-\\sin\\theta, \\cos\\theta)(−sintheta,costheta)로 이동한다. 두 기저 벡터는 여전히 서로 수직(90도)을 유지하며, 길이도 1로 변하지 않는다. 딥러닝에서 회전은 데이터의 관점을 바꾸어 특징을 학습하는 데 기여한다.
¶ 4. 투영 (Projection): 차원의 그림자
투영은 고차원의 공간을 저차원으로 납작하게 누르는 변환이다.
\\begin{bmatrix} 1 & 0 \\\\ 0 & 0 \\end
이 행렬은 x성분은 그대로 두지만(beginbmatrix10endbmatrix\\begin{bmatrix} 1 \\\\ 0 \\end{bmatrix}beginbmatrix10endbmatrix), y성분은 무엇이 들어오든 강제로 0으로 만든다(beginbmatrix00endbmatrix\\begin{bmatrix} 0 \\\\ 0 \\end{bmatrix}beginbmatrix00endbmatrix). 결과적으로 2차원 평면 위의 모든 점은 x축이라는 1차원 직선 위로 붕괴된다. 이것은 뒤에서 다룰 '특이 행렬(Singular Matrix)'의 가장 극단적인 형태이며, 정보의 비가역적 손실을 의미한다.8
¶ 5.2.4 반죽 치대기(Dough Kneading)와 행렬의 한계
행렬 변환을 설명할 때 자주 등장하는 비유 중 하나는 '반죽 치대기(Baker's Map)'이다.7 제빵사가 반죽을 넓게 펴고(Stretch), 반으로 접고(Fold), 다시 펴는 과정을 반복하면, 반죽 안의 건포도(데이터 포인트)들은 공간 전체에 고르게 섞이게 된다.
여기서 중요한 구분점이 있다. 행렬, 즉 선형 변환은 오직 '펴기(Stretch)'와 '회전(Rotate)'만을 담당한다. 선형 변환은 공간을 '접을(Fold)' 수 없다. 직선을 구부릴 수 없다는 선형성의 규칙 때문이다.
그렇다면 딥러닝 신경망은 어떻게 그 복잡한 데이터 분포를 학습하는가? 바로 **활성화 함수(Activation Function)**가 '접기'를 담당하기 때문이다. ReLU나 Tanh 같은 비선형 함수가 없다면, 아무리 많은 행렬을 곱해도 그것은 결국 하나의 거대한 선형 변환(단순히 많이 늘리고 돌린 것)에 불과하다.3 행렬이 공간을 힘껏 늘려놓으면, 활성화 함수가 그 늘어난 공간을 꺾고 접어서 복잡한 위상(Topology)을 만들어내는 것, 이것이 심층 신경망이 '반죽'을 완성하는 비결이다.
¶ 5.3 행렬식(Determinant): 공간의 압축률과 스케일
¶ 5.3.1 면적의 확장 계수
행렬식(det(A)\\det(A)det(A))은 고등학교 수학이나 대학 입문 과정에서 복잡한 공식을 통해 계산하는 '어떤 숫자'로만 기억되기 쉽다. ad−bcad-bcad−bc라는 공식보다 훨씬 중요한 것은 그 기하학적 의미다. 행렬식은 **"선형 변환에 의해 공간의 부피가 얼마나 변했는가"**를 나타내는 **스케일링 팩터(Scaling Factor)**다.1
2차원 평면에서 가로 1, 세로 1인 단위 정사각형(면적 1)을 생각해보자. 행렬 AAA에 의해 변환된 후, 이 정사각형은 평행사변형이 된다. 이 평행사변형의 면적이 바로 행렬식의 절대값 ∣det(A)∣|\\det(A)|∣det(A)∣이다.
- det(A)=3\\det(A) = 3det(A)=3: 모든 영역의 면적이 3배로 늘어났다.
- det(A)=0.5\\det(A) = 0.5det(A)=0.5: 공간이 절반으로 압축되었다.
- det(A)=1\\det(A) = 1det(A)=1: 면적이 보존된다. (회전 변환이나, 면적을 유지하는 전단 변환이 여기에 해당한다.)
3차원에서는 단위 정육면체의 부피 변화율이 되며, n차원에서도 마찬가지로 초부피(Hypervolume)의 변화율을 의미한다.
¶ 5.3.2 부호의 비밀: 공간의 뒤집힘 (Orientation)
행렬식은 음수일 수 있다. 면적이 음수라는 것은 물리적으로 말이 안 되지만, 기하학적으로는 '방향성(Orientation)'의 반전을 의미한다.21
2차원 평면에서 hati\\hat{i}hati 벡터가 hatj\\hat{j}hatj 벡터의 오른쪽에 있는 것(반시계 방향 순서)을 정방향이라고 하자. 만약 변환 후에 hati\\hat{i}hati가 hatj\\hat{j}hatj의 왼쪽으로 넘어가 버렸다면, 이는 종이를 뒤집은 것과 같은 효과다. 거울에 비친 상처럼 좌우가 바뀐 것이다. 이때 행렬식은 음수가 된다.
3차원에서는 '오른손 법칙' 좌표계가 '왼손 법칙' 좌표계로 변환되었음을 뜻한다. 예를 들어 det(A)=−2\\det(A) = -2det(A)=−2라면, 공간의 부피를 2배로 늘리면서 동시에 공간을 안팎으로 뒤집었다는 뜻이다.
¶ 5.3.3 행렬식 0과 차원의 붕괴 (The Singular Matrix)
행렬식의 기하학적 해석에서 가장 드라마틱한 순간은 det(A)=0\\det(A) = 0det(A)=0일 때다. 부피가 0이 된다는 것은 무엇을 의미하는가?
3차원 입체였던 공간이 납작한 2차원 평면(면적만 있고 부피는 0)이나, 1차원 선, 혹은 0차원 점으로 완전히 짓눌려버렸음을 의미한다. 이를 **'차원 붕괴(Dimension Collapse)'**라고 하며, 이런 행렬을 **특이 행렬(Singular Matrix)**이라고 부른다.22
직관적 비유: 유압 프레스와 그림자
3차원 공간에 있는 물체를 강력한 유압 프레스로 눌러서 종잇장처럼 납작하게 만들었다고 상상해보자. 이제 그 납작해진 종이만 보고, 원래 물체의 높이가 얼마였는지, 내부 구조가 어떠했는지 알 수 있을까? 불가능하다. 높이 정보(한 차원)가 영구적으로 소실되었기 때문이다.
또는, 어떤 물체의 그림자를 생각해보자.14 3차원 물체를 2차원 벽면에 투영(Projection)하면 그림자가 생긴다. 그림자는 물체의 정보를 담고 있지만, 깊이(Depth) 정보는 잃어버렸다. 서로 다른 위치에 있는 두 점이 그림자 상에서는 같은 점으로 겹쳐 보일 수 있다(Many-to-One Mapping).
이것이 바로 "행렬식이 0인 행렬은 역행렬(Inverse Matrix)이 존재하지 않는다"는 대수적 정리의 기하학적 이유다. 역행렬은 변환을 되돌리는 것인데, 이미 차원이 붕괴되어 정보가 뭉개져버렸다면, 원래의 상태를 유일하게 복원할 수 없기 때문이다.9
¶ 5.4 고유값과 고유벡터(Eigenvalues & Eigenvectors): 혼란 속의 질서
¶ 5.4.1 변하지 않는 축을 찾아서
행렬 AAA가 공간을 회전시키고, 늘리고, 전단시키는 대혼란 속에서도, 자신의 **방향(Span)**을 고집스럽게 유지하는 벡터들이 있다. 이들을 **고유벡터(Eigenvector)**라고 부른다.24
기하학적으로 고유벡터는 변환의 '회전축' 또는 **'스케일링의 주축'**이다. 3차원 지구본을 돌릴 때, 적도나 중위도의 점들은 맹렬히 위치를 바꾸지만, 북극점과 남극점을 잇는 자전축 위의 점들은 제자리에 있거나 축을 따라서만 움직인다. 이 자전축이 바로 회전 변환의 고유벡터다.
수식으로는 다음과 같이 정의된다:
Amathbfv=lambdamathbfvA\\mathbf{v} = \\lambda\\mathbf{v} Amathbfv=lambdamathbfv
여기서 mathbfv\\mathbf{v}mathbfv는 고유벡터, lambda\\lambdalambda는 **고유값(Eigenvalue)**이다. 행렬 AAA를 고유벡터 mathbfv\\mathbf{v}mathbfv에 적용했더니, 결과가 원래 벡터의 상수 배(lambda\\lambdalambda)가 되었다는 뜻이다. 즉, 벡터의 방향은 변하지 않고(평행하며), 길이만 lambda\\lambdalambda배로 변했다.
¶ 5.4.2 고유값 lambda\\lambdalambda: 스트레칭의 강도
고유값 lambda\\lambdalambda는 해당 고유벡터 축을 따라 공간이 얼마나 늘어나거나 줄어드는지를 나타내는 계수다.
- ∣lambda∣>1|\\lambda| > 1∣lambda∣>1: 그 축 방향으로 공간이 늘어난다 (Stretch).
- ∣lambda∣<1|\\lambda| < 1∣lambda∣<1: 그 축 방향으로 공간이 줄어든다 (Shrink).
- lambda<0\\lambda < 0lambda<0: 그 축 방향으로 공간이 뒤집히며(Flip) 스케일링된다.
- lambda=0\\lambda = 0lambda=0: 그 축 방향으로 공간이 붕괴된다. 해당 축의 차원이 사라진다.22
행렬식과 고유값의 관계:
행렬식은 모든 고유값의 곱과 같다 (det(A)=prodlambda_i\\det(A) = \\prod \\lambda\_idet(A)=prodlambda_i). 이는 매우 직관적이다. 행렬식이 부피의 변화율이라면, 고유값은 각 축(가로, 세로, 높이 등) 방향으로의 길이 변화율이다. 전체 부피 변화는 각 축의 길이 변화를 모두 곱한 것과 같아야 하기 때문이다.20 만약 고유값 중 하나라도 0이라면, 전체 곱(행렬식)도 0이 되며, 이는 한 축이 완전히 무너져 부피가 0이 됨을 의미한다.
¶ 5.4.3 주성분 분석(PCA)과 데이터의 뼈대
머신러닝, 특히 주성분 분석(PCA)에서 고유벡터는 데이터 분포의 **'가장 중요한 방향(Principal Directions)'**을 찾아내는 나침반 역할을 한다.25
고차원 공간에 데이터가 타원형 구름처럼 퍼져 있다고 가정하자.
- 가장 길게 퍼져 있는 축(분산이 가장 큰 방향)이 첫 번째 고유벡터다.
- 그 축과 직교하면서 두 번째로 넓게 퍼져 있는 축이 두 번째 고유벡터다.
이때 해당 고유값의 크기는 그 축 방향으로 데이터가 얼마나 많이(분산이 크게) 분포하는지를 나타낸다. 고유값이 매우 작은 축은 데이터의 변화가 거의 없는, 즉 정보량이 적거나 노이즈에 불과한 차원이다. PCA는 이러한 작은 고유값을 가진 차원을 과감히 버리고, 큰 고유값을 가진 축(주성분)들만 남겨 데이터를 압축하는 기술이다. 이는 뒤에 나올 LoRA와 같은 모델 압축 기술의 기초가 되는 사고방식이다.
¶ 5.5 랭크(Rank): 정보의 본질적 차원
¶ 5.5.1 차원의 거품 걷어내기
행렬의 **랭크(Rank)**는 그 행렬이 표현하는 공간의 **'실질적인 차원 수'**를 의미한다.28 100times100100 \\times 100100times100 행렬이라고 해서 반드시 100차원의 정보를 담고 있는 것은 아니다. 만약 이 행렬의 모든 열(Column) 벡터들이 하나의 직선 위에 있거나, 서로의 상수 배라면, 이 행렬은 겉보기에만 거대할 뿐 실제로는 1차원 정보밖에 담지 못한 것이다.
- Full Rank: 행렬의 크기(nnn)만큼의 차원을 온전히 보존한다. (det(A)neq0\\det(A) \\neq 0det(A)neq0, 역행렬 존재)
- Rank Deficiency: 랭크가 nnn보다 작다. 차원 붕괴가 일어난 특이 행렬이다. (det(A)=0\\det(A) = 0det(A)=0, 역행렬 없음)
랭크는 **"선형적으로 독립(Linearly Independent)인 열 또는 행의 최대 개수"**로 정의된다. 정보 이론적 관점에서 랭크는 **'중복되지 않은 고유한 정보의 양'**을 대변한다.30
¶ 5.5.2 행렬 분해와 저랭크 근사 (Low-Rank Approximation)
현대 AI와 추천 시스템에서는 "데이터 행렬이 저랭크(Low Rank) 구조를 가진다"는 가정이 매우 중요하다. 이는 복잡해 보이는 현상도 사실은 소수의 잠재 요인(Latent Factors)들에 의해 설명될 수 있다는 믿음이다.
예를 들어, 넷플릭스의 [사용자 times\\timestimes 영화] 평점 행렬은 수백만 차원이지만, 실제로는 '사용자의 취향(액션, 로맨스 등)'과 '영화의 장르적 특성'이라는 소수의 요인에 의해 결정된다. 따라서 거대한 행렬 MMM을 두 개의 날씬한(Low Rank) 행렬 UUU와 VVV의 곱으로 분해하여 근사할 수 있다.
MapproxUtimesVTM \\approx U \\times V^T MapproxUtimesVT
이 기법은 데이터의 노이즈를 제거하고(De-noising), 누락된 정보를 채우며(Matrix Completion), 저장 공간을 획기적으로 줄이는 데 사용된다.
¶ 5.6 심화 탐구: LoRA (Low-Rank Adaptation) - LLM 튜닝의 혁명
이제 지금까지 배운 선형 변환, 랭크, 행렬 분해의 개념이 최신 거대 언어 모델(LLM) 기술에 어떻게 적용되는지 살펴보자. **LoRA(Low-Rank Adaptation)**는 수학적 통찰이 어떻게 막대한 엔지니어링 비용을 절감하는지 보여주는 최고의 사례다.32
¶ 5.6.1 거대 모델 미세 조정(Fine-tuning)의 난관
LLaMA 3, GPT-4와 같은 모델은 수천억 개의 파라미터를 가진다. 특정 도메인(예: 법률, 의료, 한국어 특화)을 위해 이 모델을 미세 조정(Fine-tuning)하려면, 이론적으로는 모든 가중치 행렬 WWW를 갱신해야 한다.
W_new=W_old+DeltaWW\_{new} = W\_{old} + \\Delta W W_new=W_old+DeltaW
여기서 DeltaW\\Delta WDeltaW는 학습을 통해 업데이트될 가중치 변화량이다. 하지만 WWW가 4096times40964096 \\times 40964096times4096처럼 거대하다면, DeltaW\\Delta WDeltaW 역시 동일한 크기의 거대 행렬이다. 이를 학습하기 위해 필요한 GPU 메모리(VRAM)는 천문학적이다.
¶ [표 5-1] LLaMA-7B 모델 튜닝 시 필요한 VRAM 비교 (추정치)
34
| 튜닝 방식 (Method) | 정밀도 (Precision) | 필요 VRAM (13B 모델 기준) | 비고 |
| Full Fine-Tuning | 16-bit (FP16) | > 100 GB | 가중치 + 그레이디언트 + 옵티마이저 상태(Adam) 저장 필요. A100(80GB) 2장 이상 필요. |
| LoRA | 16-bit (FP16) | ~ 24 GB | 가중치 동결(Frozen), 어댑터만 학습. RTX 3090/4090 1장으로 가능. |
| QLoRA | 4-bit (Quantized) | ~ 12-16 GB | 기본 모델을 4비트로 양자화하여 메모리 더욱 절감. 소비자용 GPU에서 구동 용이. |
Full Fine-tuning은 기업급 클러스터가 필요하지만, LoRA를 사용하면 개인 연구자도 집에서 거대 모델을 튜닝할 수 있다. 어떻게 이런 마법이 가능할까?
¶ 5.6.2 내재적 차원(Intrinsic Dimension) 가설
2020년 연구(Aghajanyan et al.)에 따르면, 거대 언어 모델은 이미 세상의 지식을 충분히 학습했기 때문에, 특정 작업을 위해 추가로 학습할 때 실제로 변해야 하는 정보의 차원은 매우 낮다.37
즉, 가중치 변화량 행렬 DeltaW\\Delta WDeltaW는 dtimesdd \\times ddtimesd 크기의 거대한 행렬이지만, 그 랭크(Rank)는 rrr (예: 8, 16, 64) 정도로 매우 낮을 것이라는 가설이다. DeltaW\\Delta WDeltaW는 '저랭크 행렬(Low-Rank Matrix)'인 것이다.
¶ 5.6.3 LoRA의 매커니즘: 행렬 분해의 역이용
LoRA는 거대한 DeltaW\\Delta WDeltaW를 직접 학습하는 대신, 이를 두 개의 매우 작은 행렬 AAA와 BBB의 곱으로 분해하여 학습한다.32
DeltaW=BtimesA\\Delta W = B \\times A DeltaW=BtimesA
원래 가중치 행렬 WWW의 차원이 dtimeskd \\times kdtimesk이고, 랭크를 rrr로 설정했다면:
- AAA: rtimeskr \\times krtimesk 행렬 (다운 프로젝션, Down-projection)
- BBB: dtimesrd \\times rdtimesr 행렬 (업 프로젝션, Up-projection)
- rlld,kr \\ll d, krlld,k (예: d=4096d=4096d=4096일 때 r=8r=8r=8)
기하학적 해석: 병목(Bottleneck)을 통한 효율화
- 입력 데이터 mathbfx\\mathbf{x}mathbfx가 들어오면, 행렬 AAA가 이를 rrr차원의 아주 작은 저차원 공간으로 **압축(Collapse/Project)**한다.
- 이 압축된 공간에서 정보가 처리된다.
- 행렬 BBB가 이를 다시 원래의 ddd차원 공간으로 **복원(Expand)**한다.
이 과정은 데이터 흐름에 인위적인 병목(Bottleneck)을 만드는 것이다. rrr을 작게 잡는다는 것은 "모델이 변할 수 있는 자유도를 제한하겠다"는 뜻이다. 하지만 "내재적 차원 가설"에 의해, 이 제한된 자유도만으로도 충분히 원하는 튜닝 효과를 낼 수 있다.
초기화의 묘미:
학습 시작 시, AAA는 정규분포로 무작위 초기화하지만, BBB는 0(Zero Matrix)으로 초기화한다.
따라서 학습 시작점에서는 DeltaW=BtimesA=0\\Delta W = B \\times A = 0DeltaW=BtimesA=0이 되어, 모델은 기존의 사전 학습된 가중치 WWW 그대로 동작한다. 학습이 진행됨에 따라 BBB가 0에서 벗어나며 점진적으로 가중치에 변화를 주기 시작한다. 이는 기존 지식을 파괴하지 않고 부드럽게 새로운 지식을 덧입히는(Adaptation) 안정적인 학습을 보장한다.
¶ 5.6.4 성능과 트레이드오프 (Trade-off)
LoRA는 만능일까? 연구 결과에 따르면 Full Fine-tuning 대비 약 98~99% 수준의 성능을 보이거나, 때로는 대등한 성능을 낸다.39
- 장점: 압도적인 메모리 효율성, 빠른 학습 속도, 체크포인트 용량이 매우 작음(수십 MB 수준).
- 단점/한계: 수학적 추론이나 코딩과 같이 복잡한 논리 구조를 새로 배워야 하는 작업에서는 Full Fine-tuning보다 성능이 다소 떨어질 수 있다.40 랭크 rrr이 너무 작으면 모델의 표현력이 부족해지기 때문이다. 반대로 rrr을 너무 키우면 LoRA의 메모리 이점이 줄어들고, "침입 차원(Intruder Dimension)" 문제가 발생해 학습 안정성이 떨어질 수도 있다는 최근 연구 결과도 있다.38
결국 LoRA는 행렬의 랭크 개념을 이용해, 거대한 고차원 공간 속에서 **실제로 유의미한 변화가 일어나는 저차원 부분 공간(Subspace)**만을 핀셋으로 집어내어 학습시키는, 수학적으로 매우 우아한 엔지니어링 기법이다.
¶ 5.7 구현 및 시각화 가이드 (Implementation & Visualization)
이론을 실제 코드로 구현해보는 것은 이해를 돕는 가장 좋은 방법이다. Python의 NumPy나 PyTorch, 그리고 시각화 도구를 활용해 행렬의 왜곡을 직접 눈으로 확인해볼 수 있다.16
¶ 5.7.1 격자 변환 시각화 알고리즘
행렬 AAA에 의한 공간 왜곡을 시각화하는 기본적인 알고리즘은 다음과 같다.
- 격자 생성: −10lex,yle10-10 \\le x, y \\le 10−10lex,yle10 범위에 일정한 간격의 격자점(Grid Points)들을 생성한다. (np.meshgrid 활용)
- 변환 적용: 생성된 모든 (x,y)(x, y)(x,y) 좌표 벡터에 행렬 AAA를 곱한다. mathbfx′=Amathbfx\\mathbf{x}' = A\\mathbf{x}mathbfx′=Amathbfx.
- 그리기: 원래의 격자(보통 회색 점선)와 변환된 격자(실선 또는 색상)를 겹쳐서 그린다.
- 기저 벡터 표시: 원점에서 (1,0)(1,0)(1,0)과 (0,1)(0,1)(0,1)로 향하는 화살표가 어디로 이동했는지 굵은 화살표로 표시한다. 이를 통해 행렬의 열 벡터가 기저 벡터의 도착점임을 확인한다.
¶ 5.7.2 3D 툴(Blender)을 이용한 확인
Blender와 같은 3D 그래픽 툴에서도 행렬은 핵심이다. 'Shear' 기능을 사용할 때, 내부적으로는 전단 행렬(Shear Matrix)이 객체의 버텍스(Vertex) 좌표에 곱해진다.18
Python
# Blender Python API 예시 (개념적 코드)
import bpy
from mathutils import Matrix
# XY 평면에서의 전단 변환 (x축 고정, y축을 x방향으로 1만큼 밀기)
shear_matrix = Matrix([,
,
,
])
obj = bpy.context.active_object
obj.data.transform(shear_matrix)
이 코드를 실행하면 3D 모델이 엿가락처럼 비스듬히 기울어지는 것을 볼 수 있다. 이것이 바로 행렬이 수행하는 '공간 왜곡'의 실체다.
¶ 5.8 결론: 행렬, 보이지 않는 조각가
제5장에서는 행렬을 단순한 수의 나열이 아닌, 공간을 빚어내는 강력한 도구로 재조명했다.
우리는 다음과 같은 핵심 통찰을 얻었다.
- 행렬은 기계다: 입력 벡터를 받아 출력 벡터로 매핑하며, 이 과정에서 공간의 격자를 평행사변형으로 변형시킨다.
- 행렬식은 부피다: 변환 전후의 부피 비율을 나타내며, 0이 될 때 공간은 붕괴되고 정보는 영원히 소실된다(특이 행렬).
- 고유값은 축이다: 변환 속에서도 방향을 잃지 않는 축과, 그 축을 따르는 힘의 세기를 나타낸다. 이는 데이터의 주성분을 분석하거나 시스템의 안정성을 판단하는 척도가 된다.
- 랭크는 해상도다: 행렬이 담고 있는 정보의 실질적인 차원 수를 의미하며, 이를 이용해 데이터를 압축하거나 거대 AI 모델을 효율적으로 튜닝(LoRA)할 수 있다.
이제 여러분은 '행렬 곱'이라는 연산을 볼 때마다, 고차원 암흑 속에서 데이터 구름이 회전하고, 늘어나고, 투영되며 춤추는 기하학적 형상을 떠올려야 한다. 이 직관은 이어지는 장들에서 다룰 고차원 최적화(Optimization), 매니폴드(Manifold) 학습, 그리고 생성형 AI의 잠재 공간(Latent Space) 탐험을 위한 가장 든든한 나침반이 되어줄 것이다.
심화 학습을 위한 질문:
- 자신이 다루는 데이터셋의 공분산 행렬을 구하고 고유값을 계산해 보라. 0에 가까운 고유값이 있는가? 그렇다면 그 데이터는 사실 더 낮은 차원으로 압축될 수 있는가?
- 행렬식인 음수인 변환을 두 번 연속 적용하면 공간의 방향성은 어떻게 되는가? (힌트: 뒤집고 다시 뒤집으면?)
- LoRA의 랭크 rrr을 1로 설정한다면, 모델은 어떤 종류의 지식만을 학습할 수 있을까? 표현력의 극단적 제한은 어떤 결과를 초래할까?